How to Extract Text from a PDF

In this article, we’ll discuss the easiest way to accurately extract text from PDFs, images, scanned paper documents, and more.

Extracting text from PDFs is hard.
By default, most PDF readers don’t have the ability to easily read and extract text from images or image-based PDFs.
This can make it extremely difficult if your document has a lot of pages to work through, or you want to easily copy and paste from your PDF file.
Fortunately, Optical Character Recognition (OCR) makes it easy to extract text from PDFs, images, scanned documents, and more.
Read on to continue or use our helpful Table of Contents below!
What is OCR?
Optical Character Recognition (OCR) technology reads texts from images, photographs, and PDFs, then adds a layer of real text over top, effectively converting the document to real text, rather than just images of text.
OCR technology makes it possible to search, copy, paste, and edit text easier than ever; and is used for PDFs, photographs, screenshots, scanned paper documents, and more.
How to Extract Text from PDF
This applies to scanned documents, and image or picture files such as PNG & JPG:
To extract text from a PDF document, you’ll need a PDF editor with OCR technology. We use PDF Pro + OCR for all our text extracting, editing, and creating needs.
1. Open your PDF in PDF Pro + OCR.
2. Press the OCR tab, then press Current file.
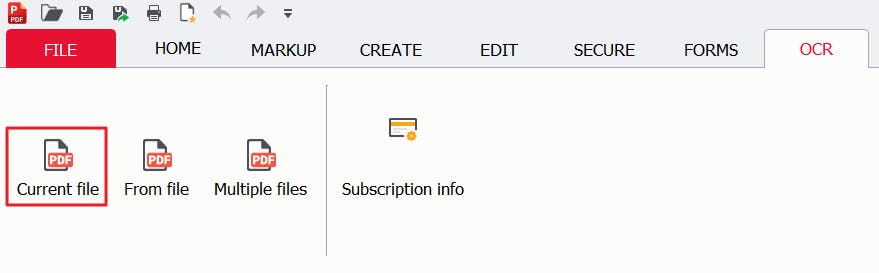
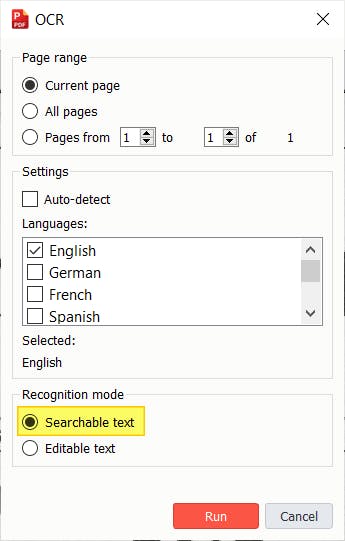
3. Specify your settings, making sure to select Searchable PDF, then press Run.
How to Extract Text from a Virtual Printer PDF
This applies to PDFs created through a virtual printer:
Copy & Paste PDF: One of the simplest ways to “extract” text is by copy and pasting.
1. With your mouse, select and highlight the text you wish you extract
2. Press [ctrl + c] on your keyboard, or right-click and select Copy.
3. Open the destination that you’d like to extract the text to, then press [ctrl + v] on your keyboard, or right-click and select Paste.
Convert PDF to a Different Program:
You can also extract text from a PDF by converting the (virtual printed) PDF document into another the file format of a word processor or similar application.
1. Open your PDF document in PDF Pro.
2. Click the Create tab, then find & click the new file format you wish to extract your text to (Word, Excel, HTML, etc.)
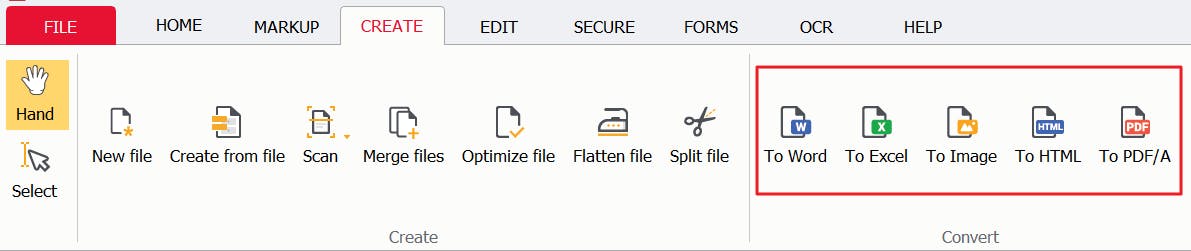
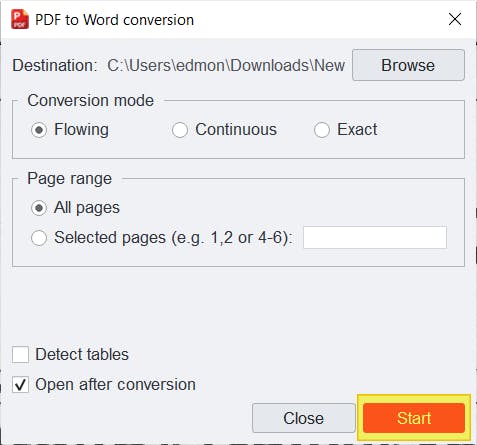
3. Press Start.
Type of text you can extract from PDFs
You’ll probably have specific kinds of documents that you work with regularly.
Some common examples of extractable text include:
- Application forms
- Invoices
- Purchase orders
- Receipts
- Bank statements
- Contracts
- Shipping orders
- Reports
- Fillable PDF forms
- Important notes
- Textbooks and eBooks
- Scope of Work
The Easiest Way to Convert PDF to Text: PDF Pro + OCR
Extracting text from PDFs is hard without OCR software. Optical Character Recognition (OCR) reads the text found in pictures, images, and image-based PDFs, and converts it to text you can interact with. For example, turning a scanned PDF form into an editable PDF form.
If you want to extract text from PDFs on your Windows computer, we recommend PDF Pro + OCR, our flagship all-in-one PDF and OCR tool.
Extracting text from PDFs is just the beginning.
PDF Pro can also help you:
- Convert PNG to PDF
- Convert TIFF to PDF
- Save a screenshot as a PDF
- Make a PDF searchable
- Make a PDF editable
- Edit a Fillable PDF
- Add a page to a PDF document
Do you need to convert a PDF to text? Download PDF Pro + OCR for free today or Buy Now!


Discover PDF PRO
PDF Pro is a desktop software for Windows & Mac distributed by PDF Pro Software Inc. The software "PDF Pro" and the company "PDF Pro Software Inc." are in no way affiliated with Adobe. The PDF file format is an open file format published under ISO 32000-1:2008
© 2017 - 2026, PDF Pro Software Inc. All rights reserved.